
Was ist XBRL? – „Ein Blick unter die Motorhaube“
XBRL ist eine Sprache aus XML-Familie. Äußerlich haben XML– und XBRL-Dokumente eine gewisse Ähnlichkeit mit einem HTML-Dokument. Beide verwenden Tags, Begriffe in spitzen Klammern wie etwa: <Dies_ist_ein_Tag>. Während die Sprache HTML in erster Linie für die Darstellung und Formatierung eines Textes im Browser zuständig ist, sind XML und XBRL daraufhin konzipiert, die Bedeutung der Textinhalte zu markieren.
Hierzu ein kleines Beispiel als Auszug aus einem XBRL-Dokument (einem sogenannten XBRL Instance Document), das die Daten eines Jahresabschlusses enthält:
<t:P123
contextRef=„31DEC2014“
unitRef=„EUR“ …>
209343000
</t:P123>
Das hier etwas verkürzt wiedergegebene Element (die XBRL-Gemeinschaft spricht hier von einem Fact, Plural: Facts) befasst sich mit einer Position einer Bilanz. Die Wertangabe lautet auf 20.934.000,00 Währungseinheiten, bei der Währung handelt es sich um EUR (Euro) und der Zeitpunkt ist der 31. Dezember 2014.
Noch offen ist, um welche Position es sich konkret handelt. Dies sagt uns der Tag, der Begriff, der mit einer spitzen Klammer beginnt. Hier lautet er „t:P123“. Er ist eindeutige Kennung und gleichzeitig der Link zur entsprechenden Taxonomie. In der Taxonomie findet sich unter diesem Begriff ein sogenanntes Concept, aufgrund dessen sie sagen kann,
- dass es ein Element „P123“ tatsächlich gibt,
- dass in diesem Fall ein Zahlenwert erwartet wird,
- dass es dazu Klartextbezeichnungen gibt, z.B. „Vorräte“, „Inventory“ und mögliche weitere,
- wie das Element rechnerisch und/oder logisch mit anderen zusammenhängt,
- in welcher externen Quelle (z.B. Gesetzesparagraf) dazu fachliche Hintergründe zu finden sind.
Hieran wird deutlich, dass Instance Document und Taxonomie (Taxonomy) untrennbar zusammengehören. Das Instance Document enthält den konkreten Bericht und geht auf die Reise vom Informationsgeber zum Empfänger. Die Taxonomie, da sie sich durch den Berichtsvorgang nicht ändert, braucht nicht übermittelt zu werden; sie ist dem Geber und dem Empfänger gleichermaßen bekannt, die sie aus der gleichen Quelle (normalerweise einer öffentlich zugängigen) bezogen haben.
Das Zusammenwirken von Instance Document und Taxonomie wird mit am Beispiel eines Berichtselements (Fact einerseits, Concept andererseits) in der Grafik dargestellt.
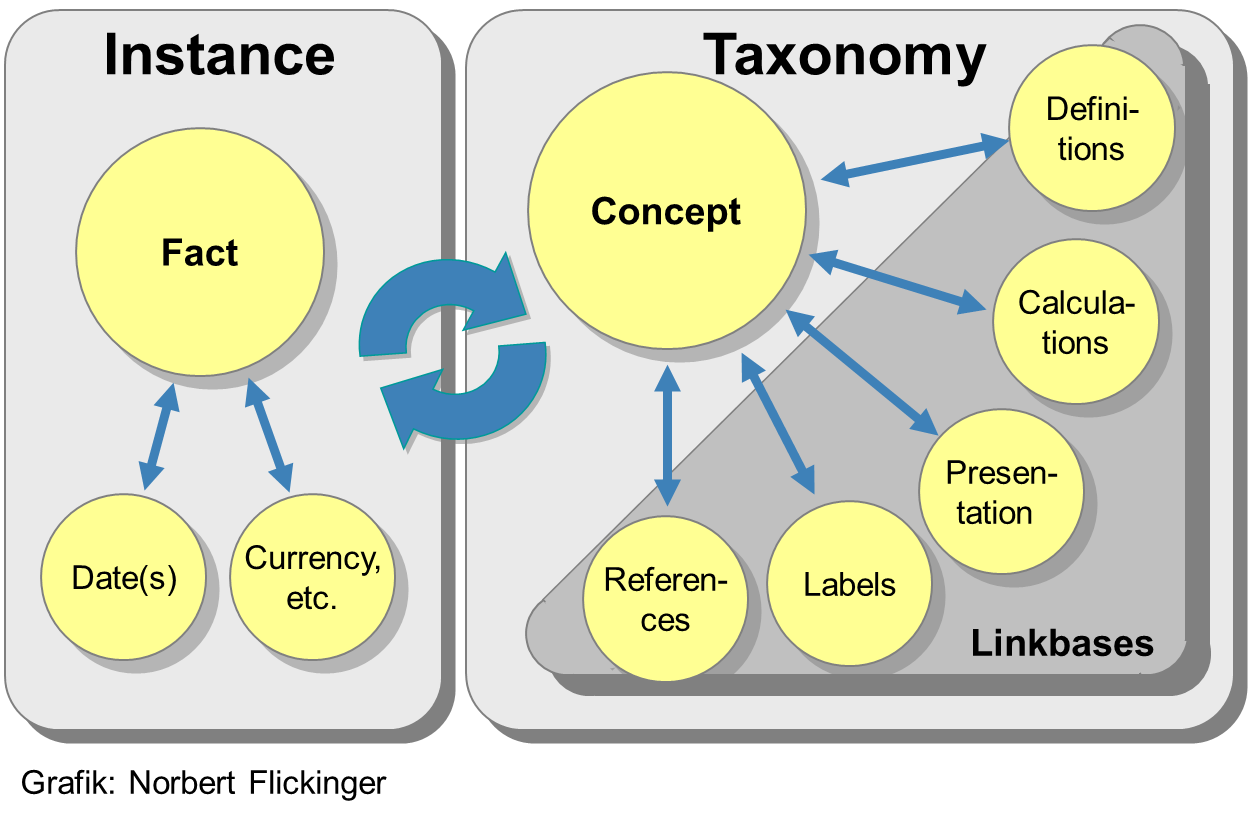
Eine Taxonomie besteht aus mehreren XML-Dokumenten, die eine logische Einheit bilden. Die wichtigsten sind
- eine Sammlung von Concepts, also kleinen Informationseinheiten, wie in unserem Fall die Definition der Bilanzposition Vorräte; ein Instance Document darf/kann nur solche Positionen verwenden, für die in der zugehörigen Taxonomie auch ein Concept vorhanden ist;
- eine Label Linkbase mit den Klartextbezeichnungen der Concepts; dabei können Labels in verschiedenen Sprachen gleichzeitig vorgehalten werden;
- eine Calculation Linkbase, die einfache rechnerische Zusammenhänge dokumentieren kann (Beispiel: „Vorräte“ sind eine Komponente des „Umlaufvermögens“, dieses ist Bestandteil der „Summe Aktiva“ und so weiter);
- eine Presentation Linkbase mit einer Standard-Darstellungsform von Jahresabschlüssen;
- eine Reference Linkbase, die Verweise auf externe Informationsquellen (etwa Gesetzesparagrafen) enthält;
- eine Definition Linkbase für logische Zusammenhänge von Concepts, die nicht rechnerischer Art sind.
Für speziellere Zwecke existieren weitere Linkbases. Nicht alle Taxonomien enthalten alle potentiell möglichen Linkbases.



